Architecture of Swignition
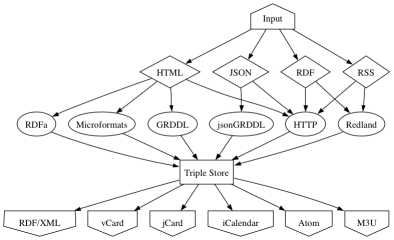
When Swignition is given a URI, it will retrieve the resource and check the media type of the response. Depending on the media type, it will create an instance of a Swignition HTML parser, or a Swignition JSON parser, and so forth. (For clarity, only some of these media type parsers are shown in the diagramme.)
Each of these parsers relies on a collection of parsing modules. For example, the HTML parser calls upon modules to handle RDFa, Microformats, GRDDL, eRDF and so on. Some parsing modules are shared between different media types. (For clarity, only some of these parsing modules are shown in the diagramme.)
Note that the parsing module labelled "HTTP" in the diagramme is not something responsible for fetching resources, but is a module that examines the resource's HTTP headers and converts useful information there (e.g. Content-Type, Last-Modified, etc) into RDF.
Each parsing module creates an RDF graph which is merged into the parser's triple store. Once the data has arrived in the triple store, information gleaned from Microformats sits alongside data from RDFa and so on. The triple store can be thought of as a big bucket of information.
Various output modules exist which read data from the triple store and output it in a variety of formats. For example, the vCard output module will scan through the triple store, looking for resources which look like people and organisations, and write out a vCard for each contact. (For clarity, only some of these output modules are shown in the diagramme.)
Note that unlike many other semantic web tools, there isn't an arrow on the diagramme going from, say, hCard to vCard and another from hCalendar to iCalendar and so on. Instead all the information goes into one bucket, and all the output modules pull their data from that one bucket. This allows for an hCard to gain information from other sources (e.g. RDFa) during its conversion to vCard.

